No podemos llamarnos con confianza expertos en administración de archivos de Linux sin ser competentes en el procesamiento de texto. Tres herramientas de línea de comandos conocidas (grep, sedy awk) han construido su reputación como procesadores de texto de Linux. Vienen preinstalados en todas las principales distribuciones del sistema operativo Linux, por lo que no es necesario consultar su existencia a través del administrador de paquetes de Linux.
Aunque los comandos grep, sed y awk tienen propiedades únicas en sus capacidades de procesamiento de texto, algunos escenarios simples obligan a que su funcionalidad se superponga ligeramente.
Por ejemplo, los tres comandos facilitan la consulta de archivos en busca de posibilidades de coincidencia de patrones y reenvían los resultados de la consulta a la salida estándar.
Este artículo tiene como objetivo identificar claramente los factores distintivos entre estos tres comandos de procesamiento de texto.
Además, este trabajo pretende extraer las siguientes conclusiones:
- Si está buscando una solución simple de coincidencia e impresión de texto, consulte grep Ordenar.
- Si está buscando otras soluciones de conversión de texto como sustituto) en la parte superior del texto emparejado e impreso, consultar sed Ordenar.
- Si está buscando una gran cantidad de procesamiento de texto en un potente lenguaje de secuencias de comandos, consulte awk Ordenar.
planteamiento del problema
Para que este tutorial sea más informativo y relevante, definamos un archivo de texto de muestra al que haremos referencia.Considere el archivo de texto creado a continuación, llamado syslog.txt Estampa varias actividades del sistema en función de una marca de tiempo específica.


comando grep en Linux
Por definición, grep El comando compara e imprime texto en función de un patrón de expresión regular. Es una solución rápida para consultar si existe una línea específica en el archivo de destino.
Su sintaxis de uso es la siguiente:
$ grep [OPTION...] PATTERNS [FILE...]
En la sintaxis anterior, patrón Representa un patrón de expresión regular definido por el usuario grep El comando se referirá a.
Buscar coincidencias de patrones de expresiones regulares en líneas definidas por el usuario
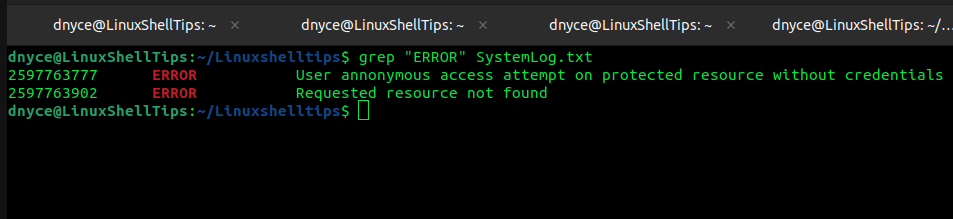
En referencia al archivo de registro del sistema que creamos anteriormente, digamos que queremos resaltar todo error eventos en el archivo, nuestro grep El comando se verá así:
$ grep "ERROR" SystemLog.txt
Este grep El comando buscará cualquier ocurrencia de la línea. error en el interior syslog.txt El archivo antes de imprimir los resultados en la salida estándar.
Coincidencia de línea invertida
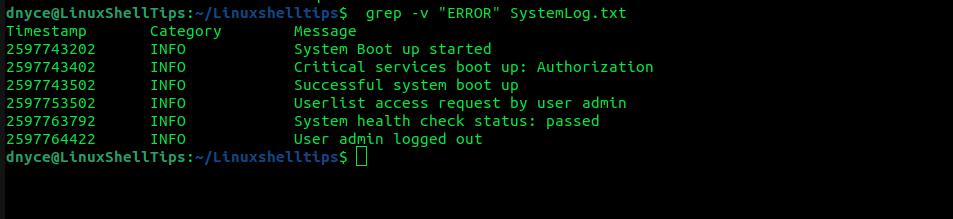
Supongamos que queremos imprimir todas las líneas del archivo excepto las líneas especificadas en el comando grep.En este caso usaremos -v opciones
$ grep -v "ERROR" SystemLog.txt
imprimir líneas delanteras y traseras
imprimir 4 líneas después error Coincidencia de línea:
$ grep -A 4 "ERROR" SystemLog.txt

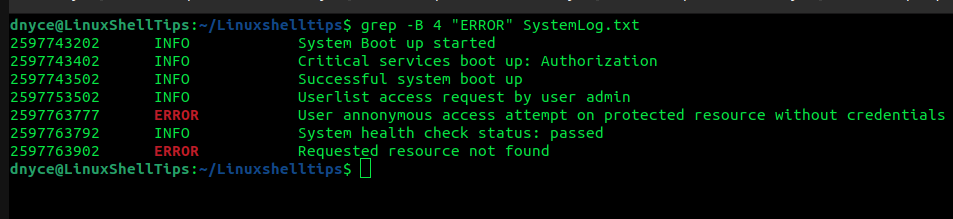
imprime las primeras 4 lineas error Coincidencia de línea:
$ grep -B 4 "ERROR" SystemLog.txt
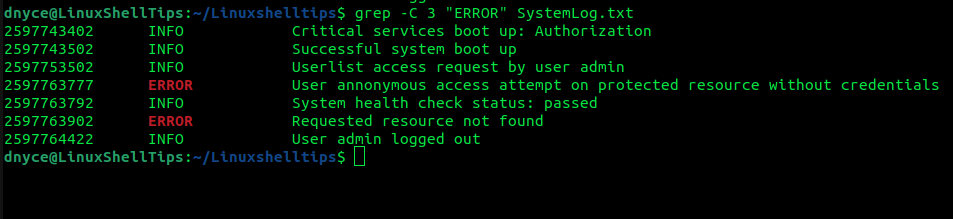
imprime 3 lineas antes y despues error Coincidencia de línea:
$ grep -B 3 "ERROR" SystemLog.txt
comando sed en Linux
Este sed El comando tiene una ventaja grep debido a sus capacidades adicionales de procesamiento de texto.
Su sintaxis de referencia es la siguiente:
$ sed [OPTION]... {script-only-if-no-other-script} [input-file]...
usar sed como grep
Este sed equivalente a grep Comando para buscar e imprimir la entrada del archivo asociada a la línea error como sigue:
$ sed -n '/ERROR/ p' SystemLog.txt

Este -n opción para prevenir sed De cada scanline se imprime.
reemplazar la cadena coincidente con reemplazar
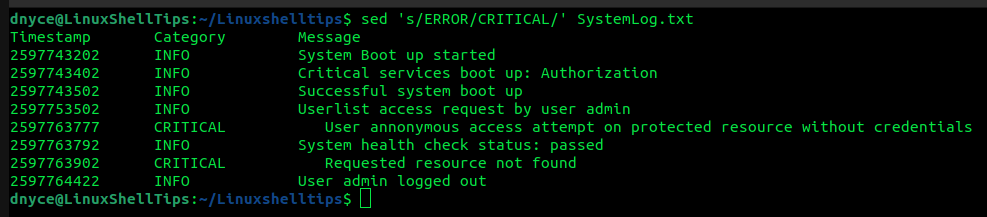
Supongamos que deseamos reemplazar la línea error línea falla En nuestro archivo de texto, sed La implementación del comando se ve así:
$ sed 's/ERROR/CRITICAL/' SystemLog.txt
Modificar archivos en su lugar
usar logotipo -i junto con un sufijo definido por el usuario para habilitar sed Cree una copia de seguridad del archivo de entrada antes de aplicar acciones persistentes previstas por el usuario.
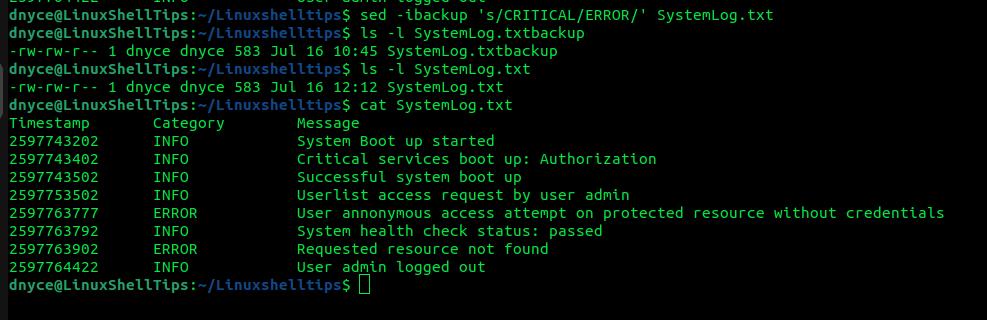
Por ejemplo, podemos cambiar el nombre de la línea Crítico espalda error Solo después de crear una copia de seguridad del estado del archivo original.
$ sed -ibackup 's/CRITICAL/ERROR/' SystemLog.txt
Se cambiará el nombre del archivo original a SystemLog.txt Backup.
$ ls -l SystemLog.txtbackup
También podemos confirmar que el archivo ha cambiado con el comando cat:
$ cat SystemLog.txt
Restringir sed a un número de línea específico
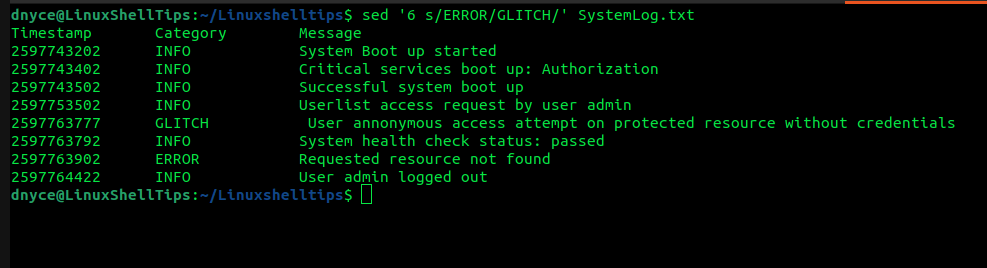
límite sed Operaciones con números de línea 6 archivo de texto que implementa:
$ sed '6 s/ERROR/GLITCH/' SystemLog.txt
Para especificar acciones de 2 a 4, implemente:
$ sed '2,4 s/INFO/NOTE/' SystemLog.txt
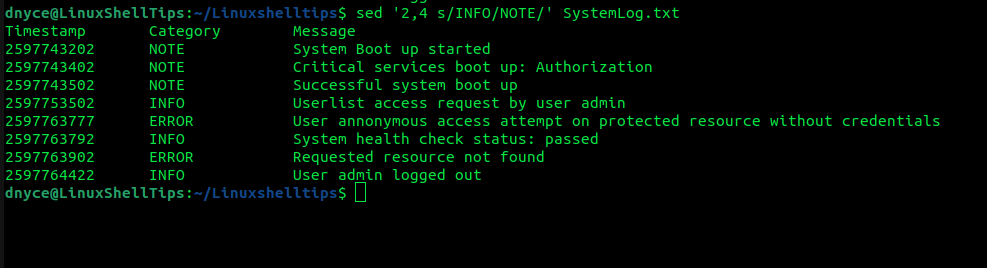
Para imprimir una coincidencia de patrón que comience en una línea específica, digamos la línea 5, implemente:
$ sed -n '5,/INFO/ p' SystemLog.txt

Comando awk en Linux
Este awk El comando se puede usar para realizar manipulaciones de tiempo, aritmética y cadenas porque tiene una gran cantidad de operaciones integradas. Además, los usuarios pueden definir sus funciones personalizables.
Su sintaxis básica es la siguiente:
$ awk [options] script file
reemplazar grep con awk
Este awk equivalente a grep El comando para buscar una línea en un archivo es el siguiente:
$ awk '/ERROR/{print $0}' SystemLog.txt

reemplazar cadena coincidente
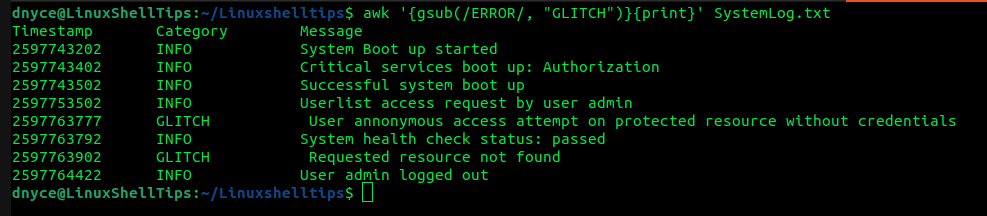
Este awk uso de comandos g-sub (un método incorporado) para operaciones de reemplazo de filas.
$ awk '{gsub(/ERROR/, "GLITCH")}{print}' SystemLog.txt
Agregar encabezados y pies de página
Podemos agregar encabezado y pie de página al archivo de entrada usando awk comienzo y final Un bloque como el siguiente:
$ awk 'BEGIN {print "SYS LOG SUMMARY\n--------------"} {print} END {print "--------------\nEND OF LOG SUMMARY"}' SystemLog.txt

operación de columna
por algo como CSV Un archivo con una estructura fila-columna, podemos imprimir solo la primera y segunda columna o la primera y tercera columna según la elección del usuario.
$ awk '{print $1, $2}' SystemLog.txt

separador de campo personalizado
implementación por defecto de awk El comando reconoce los espacios como delimitadores. Si el texto que se procesa utiliza caracteres como comas o puntos y comas como delimitadores, puede especificarlos de las siguientes formas:
$ awk -F "," '{print $1, $2}' SystemLog.txt
or
$ awk -F ";" '{print $1, $2}' SystemLog.txt
operaciones aritmeticas
Podemos contar el número de ocurrencias de esta línea información en un archivo de texto de la siguiente manera.
$ awk '{count[$2]++} END {print count["INFO"]}' SystemLog.txt
Comparación numérica
Este awk Los scripts pueden interpretar fácilmente los valores como números, no solo como cadenas. Por ejemplo, podemos recuperar entradas de archivos con marcas de tiempo anteriores a 2597763777 mediante:
$ awk '{ if ($1 > 2597763777 ) {print $0} }' SystemLog.txt

Ahora podemos distinguir completamente entre la simplicidad y la complejidad asociadas con grep, sedy awk El comando depende de la profundidad de procesamiento de texto que queramos lograr.
Espero que hayas encontrado esta guía de artículos informativa. Siéntase libre de dejar un comentario o retroalimentación.