Como administrador de Linux o usuario avanzado, dominar la administración de archivos en cualquier distribución de sistema operativo Linux que esté utilizando es primordial. La gestión de archivos es un aspecto central de la administración del sistema operativo Linux y, sin ella, no podríamos adoptar características relacionadas con archivos como el cifrado de archivos, la gestión de usuarios de archivos, el cumplimiento de archivos, las actualizaciones y el mantenimiento de archivos y la gestión del ciclo de vida de los archivos.
En este artículo, veremos un aspecto importante de la administración de archivos de Linux que consiste en dividir archivos grandes en partes en números de línea determinados. Si el objetivo de este artículo fuera simplemente dividir un archivo grande en archivos pequeños manejables sin tener en cuenta los números de línea del archivo, entonces todo lo que necesitaríamos es la conveniencia de la separar dominio.
Tabla de Contenidos
Archivo de referencia de muestra
Para que este tutorial tenga sentido, presentaremos un archivo de texto de muestra para que actúe como el archivo grande que deseamos dividir a partir de los números de línea dados. Cree un archivo de texto de muestra y complételo como se muestra.
$ sudo nano sample_file.txt
Abra este archivo con el comando cat para anotar sus números de línea asociados:
$ cat -n sample_text.txt
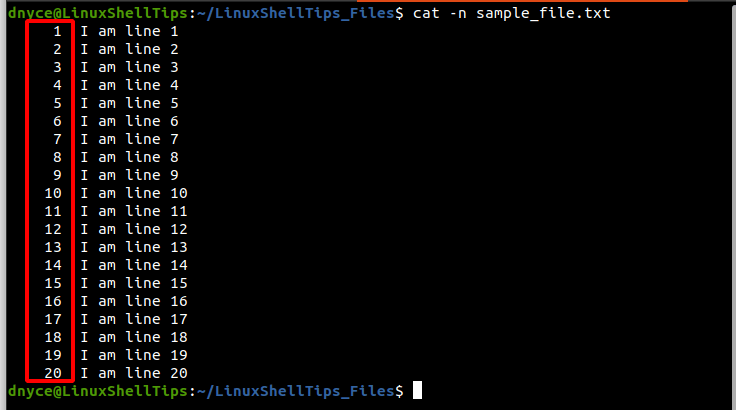
Como ha notado, el archivo anterior tiene 1 para 20 Línea de números. Ahora digamos que queremos dividir este archivo en 4 partes en números de línea 5, 11y 17.
Resultaríamos con los siguientes archivos:


- file_1 que contiene las líneas 1 a 5 de sample_file.txt.
- file_2 que contiene las líneas 6 a 11 de sample_file.txt.
- file_3 que contiene las líneas 12 a 17 de sample_file.txt.
- file_4 que contiene las líneas 18 a 20 de sample_file.txt.
Ahora que hemos entendido la declaración de nuestro problema, es hora de ver las metodologías necesarias para una solución viable.
1. Uso de los comandos de cabeza y cola
La eficacia de combinar estos dos comandos para dividir un archivo grande en partes a partir de los números de línea proporcionados requiere la inclusión del -n opción como parte de la ejecución de su comando.
Para extraer números de línea 6 para 11ejecutaremos el siguiente comando.
$ tail -n +3 sample_file.txt | head -n $(( 11-6+1 ))

Para guardar esta salida en archivo_2.txt:
$ tail -n +6 sample_file.txt | head -n $((11-6+1)) > file_2.txt $ cat file_2.txt

2. Usando el comando sed
Desde el sed El comando admite dos rangos de direcciones dados, podemos extraer líneas 12 para 17 en la siguiente manera.
$ sed -n '12,17p; 18q' sample_file.txt

Podemos modificar el comando para guardar la salida anterior en archivo_3.txt.
$ sed -n '12,17p; 18q' sample_file.txt > file_3.txt $ cat file_3.txt

3. Usando el comando awk
Él awk El comando admite numerosas funciones como redirección, bucles y matrices. Por lo tanto, podemos usarlo para crear todas las partes de archivos necesarias (archivo_1.txt, archivo_2.txt, archivo_3.txty archivo_4.txt) de un archivo grande (archivo_muestra.txt) con una sola frase de comando como se muestra a continuación.
Él awk El comando se proporciona con los números de línea clave (5, 11y 17) necesario en la división archivo_muestra.txt en cuatro partes (archivo_1.txt, archivo_2.txt, archivo_3.txty archivo_4.txt).
$ awk -v nums="5 11 17" '
BEGIN {
c=split(nums,b)
for(i=1; i<=c; i++) a[b[i]] j=1; out = "file_1.txt" } { print > out }
NR in a {
close(out)
out = "file_" ++j ".txt"
}' sample_file.txt
El resultado de ejecutar lo anterior awk comando es evidente en la siguiente captura de pantalla.

Ahora podemos dividir cómodamente archivos grandes en partes en función de los números de línea proporcionados a través de varios enfoques, como se describe en este tutorial.
También te puede interesar leer los siguientes artículos relacionados: